4. Cluster Management
A cluster is a logical division of the platform’s physical resources used to differentiate service nodes with different configuration specifications and storage types, such as X86 computing clusters, ARM computing clusters, SSD storage clusters, or commercial storage clusters. A data center can support deployment of multiple computing and storage clusters, and a cluster is typically composed of a group of physically identical nodes with the same CPU/memory, disk type, and operating system.
The cloud platform supports unified management of heterogeneous computing clusters such as X86, ARM, and GPUs, and can also manage multiple architecture storage clusters such as SSD, STAT, and NVME. Users can deploy virtual resources in different computing clusters and mount block storage devices from different storage clusters for their virtual resources.
When a server is a computing & storage fusion node, nodes with different disk types are divided into one cluster, such as an SSD computing node cluster; when the server is an independent storage node, nodes with different disk types are divided into one cluster, such as an SATA storage node cluster. Typically, the servers in a cluster are recommended to be connected to the same group of access switches, and business data networks are transmitted only within the cluster.
The platform supports administrators to easily manage and maintain the computing clusters, storage clusters, and external storage clusters of the data center, and can also control the permissions of these clusters, which can be used to allocate some physical resources exclusively to one or part of the tenants for use, suitable for dedicated private cloud scenarios.
4.1 Computing Clusters
A computing cluster is a group of physically identical computing nodes (physical machines) with the same configuration and usage, used to deploy and host virtual computing resources on the platform. A data center can deploy multiple computing clusters of different types, such as X86 clusters, ARM clusters, GPU clusters, etc., and different clusters can run different types of virtual machine resources. For example, a GPU cluster can provide GPU virtual machines for tenants, while an ARM cluster can provide virtual machines based on ARM or localized OS for tenants.
To ensure high availability of virtual machines, the platform provides virtualization intelligent scheduling strategies based on the cluster dimension, including scatter deployment, online migration, and failure migration. That is, virtual resources can be scheduled, deployed, and migrated to any computing node in the cluster, enhancing the availability of business services.
- Scatter deployment means that when a tenant creates a virtual machine, the platform will default to deploy the virtual machine on as many nodes in the cluster as possible to ensure the availability of its business services in case of hardware or software failures.
- Online migration means that the platform administrator manually migrates a virtual machine from one physical machine in the cluster to another, releasing the resources of the source physical machine.
- Failure migration means that when the physical machine running the virtual machine experiences an anomaly or failure, causing it to shut down, the scheduling system will automatically migrate the virtual resources it carries to a physically healthy and normally loaded machine within the cluster, as much as possible ensuring the availability of business services.
Based on the logic of online migration and failure migration, it is usually recommended to plan physical machine nodes with the same CPU and memory configurations into one computing cluster to avoid abnormal or unavailable startups due to inconsistent CPU architecture or configurations after virtual machine migration.
By default, the platform sets the cluster name based on the CPU platform architecture, and administrators can modify the cluster name according to the platform’s own usage situation. The platform also supports administrators to view and manage computing clusters and physical machines and computing instances within the computing clusters, such as modifying cluster permissions, online migrating computing instances, etc.
4.1.1 View Computing Clusters
Administrators can access the computing cluster management console through the 【Clusters】 > 【Computing Clusters】 option in the navigation bar or through the 【Computing Clusters】 option in the 【Region Details】 page for specific regions.
Through the computing cluster console, administrators can view the list of all computing clusters and their associated information for a specific region, including cluster ID, cluster type, cluster type name, CPU usage, physical GPU usage, memory usage, and creation time, as shown in the following figure:
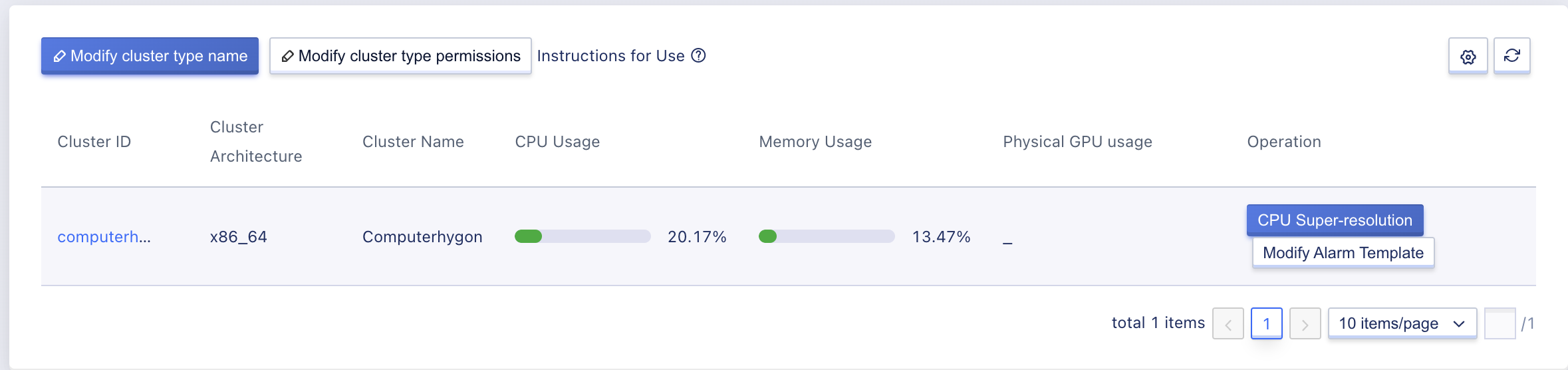
- Cluster ID: The unique identifier of the cluster in the platform, such as set-01, set-02.
- Cluster type name: The name that represents the cluster, which is the model on the tenant side. When creating a virtual machine, tenants can choose different clusters to deploy virtual machines.
- CPU usage: The total number of vCPU cores in the cluster, which is the number of vCPU cores that platform users can apply for in the cluster.
- Physical GPU usage: The total number of GPU devices on all physical nodes in the cluster.
- Memory usage: The total amount of memory in the cluster, which is the amount of memory that platform users can apply for in the cluster.
- Creation time: The creation time of the computing cluster.
If a cluster’s allocated vCPU and memory ratio exceeds 80%, it indicates that there are relatively few available vCPU and memory resources in the region, and expansion may be necessary. Tenants can also be monitored for their use of cloud resources, with cloud resources being released in a timely manner to ensure that users who truly need to use the resources can be allocated the cloud resources.
Administrators can also enter the cluster details page by clicking on the cluster name or the detail button in the list, where they can manage physical machines and all computed instances within the cluster.
(1)The computing cluster overview page shows the basic information and monitoring information of the computing cluster:
- Basic information mainly displays information such as cluster ID, cluster type, cluster architecture, total number of cores, allocated cores, total memory, allocated memory, creation time, etc.
- Monitoring information mainly displays the usage trends of CPU cores (including total, allocated, and unallocated) and memory capacity (including total, allocated, and unallocated) in the cluster.
Host management refers to the management of all computing nodes in the cluster, such as locking, entering maintenance mode, etc. See the Host Management section in Physical Resource Management for more details.
(3)Computing instance management refers to the management of all computing instances in the cluster, such as online migration. See section Computing Instance Management .
4.1.2 Modify Cluster Type Name
The cluster type represents a cluster. By default, the platform sets the cluster name based on the CPU platform architecture, and administrators can rename the cluster to a more recognizable name based on their own usage needs.
After modifying the cluster type name, the model name that users select when creating virtual resources will be synchronized with the cluster name. Modifying the name does not affect the normal operation of the cluster and its resources, and can be modified at any time. Administrators can click “Modify Cluster Type Name” in the computing cluster list and enter a new name to change the cluster type name, as shown in the following figure:
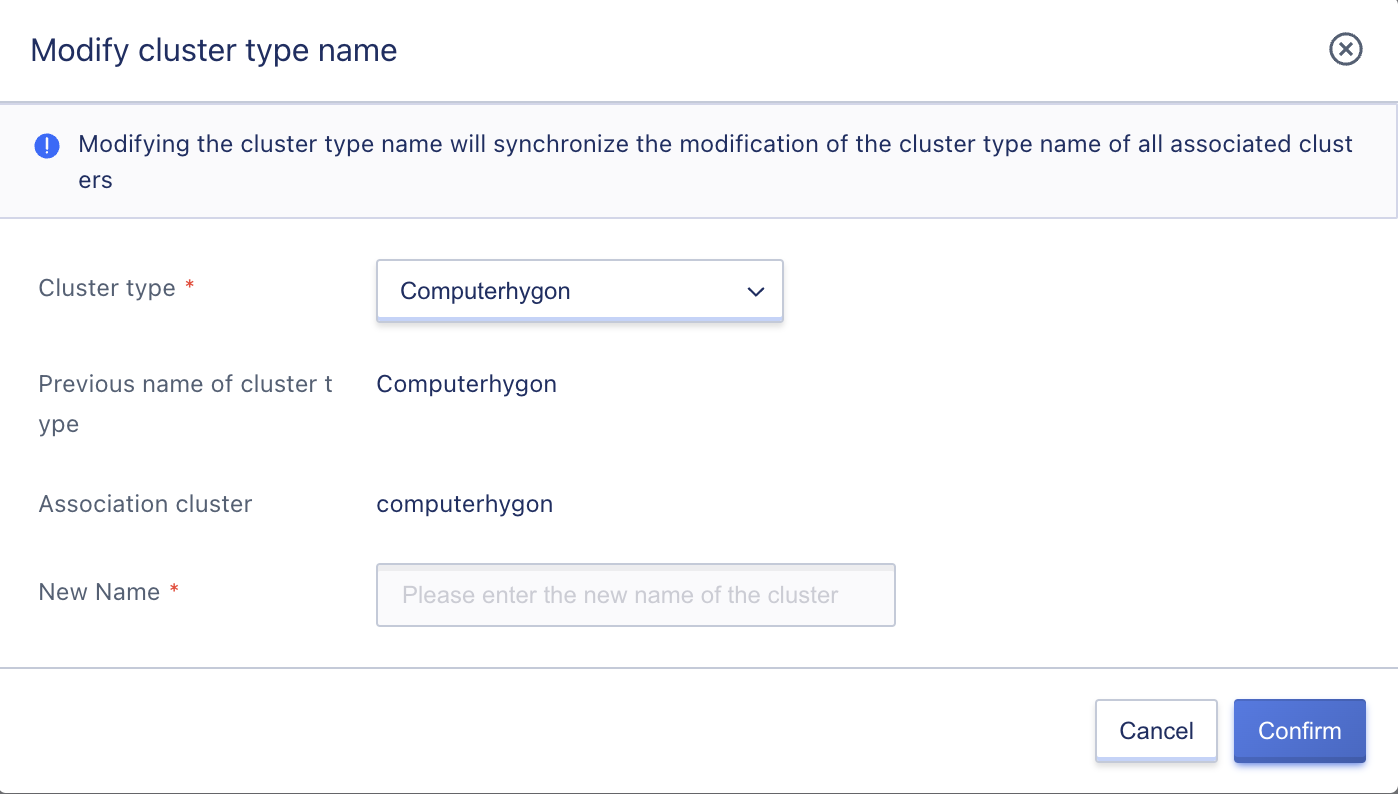
The cluster type and cluster name are concepts that are equivalent on the platform, i.e., one cluster type represents one cluster.
4.1.3 Modifying Cluster Permissions
By default, the platform’s computing cluster is open to all tenants. However, the platform supports permission control for computing clusters that is used to allocate some physical computing resources to one or more specific tenants, suitable for exclusive private cloud scenarios. After modifying the cluster permissions, the cluster can only be accessed and used by the specified tenants, while unauthorized tenants cannot view or use the restricted cluster to create virtual resources.
In an application scenario, special model physical server clusters and GPU physical server clusters can be opened to only a few tenants with critical business running on designated clusters. For example, assume there are 50 hyper-converged physical servers, and tenant A has exclusive access to 30 of them, while tenants B, C, and D share the remaining 20. To address this issue, the following solution can be implemented:
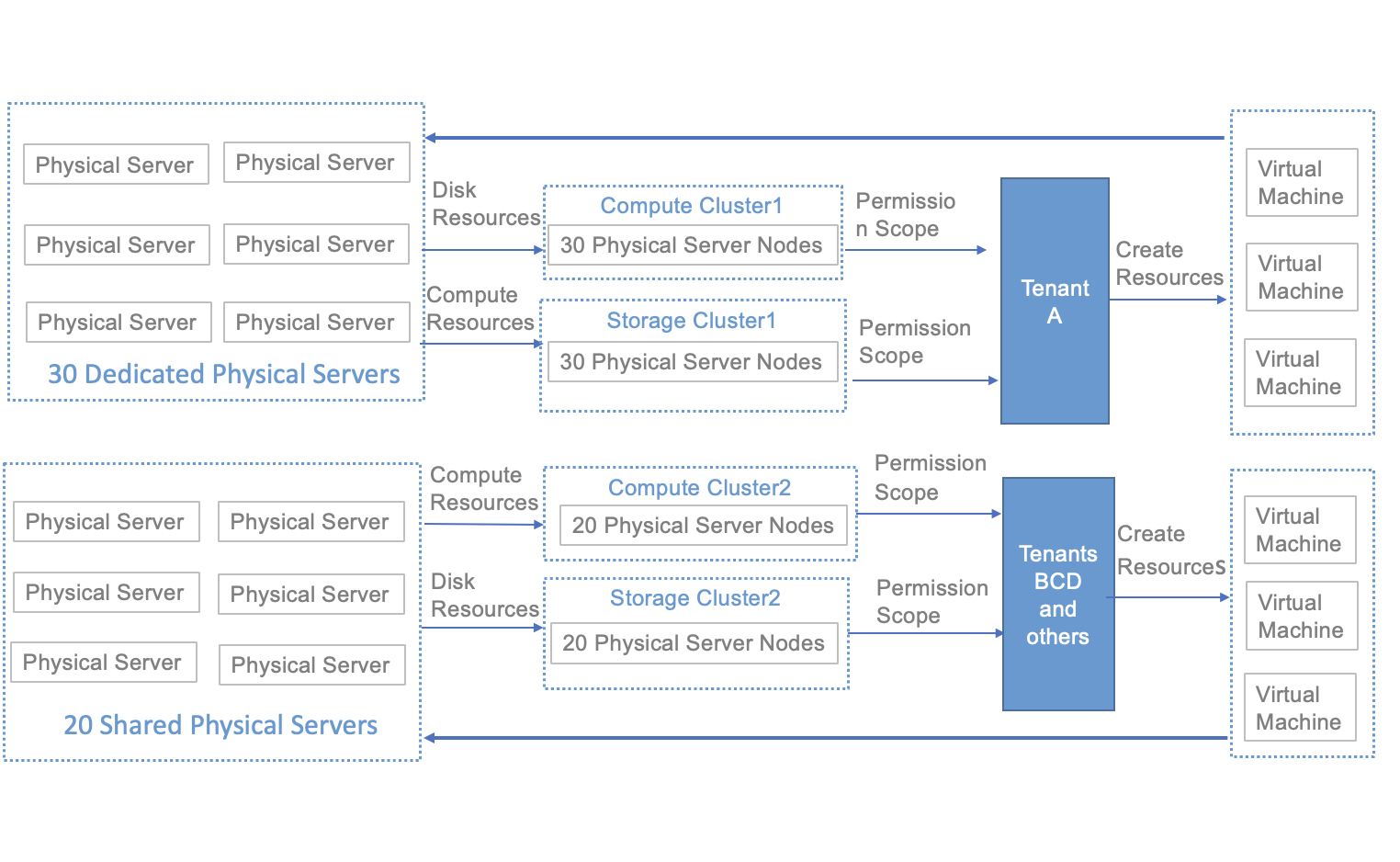
To ensure that tenants can exclusively access some physical machines, physical machines that need exclusive access should be partitioned into an independent computing cluster when deploying physical resources in the platform. At the same time, storage resources of these physical machines should be allocated to an independent storage cluster. The allocated computing and storage clusters must be assigned to the exclusive tenant to ensure that the assigned computing and storage resources come from the same exclusive physical machine.
- When deploying the platform, plan to allocate 30 physical servers to the same computing cluster (cluster 1) while the remaining 20 servers are partitioned into a different computing cluster (cluster 2).
- At the same time, allocate the disk resources of the 30 physical servers to the same type of storage cluster (storage cluster 1), while allocating the remaining 20 storage resources to a different storage cluster (storage cluster 2).
Through the above solution, the computing resources and storage resources of 30 physical servers have been partitioned into independent resource pools at the physical layer and platform logical layer. The permissions for using computing cluster 1 and storage cluster 1 have been configured for tenant A through the “Cluster Type Permissions” of the platform.
At this point, when creating virtual machines, disks, snapshots, load balancers, NAT gateways, and VPN gateway instances, Tenant A can choose the “Computing Cluster 1” model and “Storage Cluster 1” storage type. Tenants B, C, and D cannot view computing cluster 1 and storage cluster 1 when creating resources and therefore cannot create relevant resources on this exclusive cluster. This ensures that computing cluster 1 and storage cluster 1’s computing and storage resources are exclusively used by Tenant A.
Platform administrators can click “Modify Cluster Type Permissions” in the computing cluster list to assign tenant permissions as “All Tenants” or “Specified Tenants” to designate a cluster to specific tenants, as shown below:
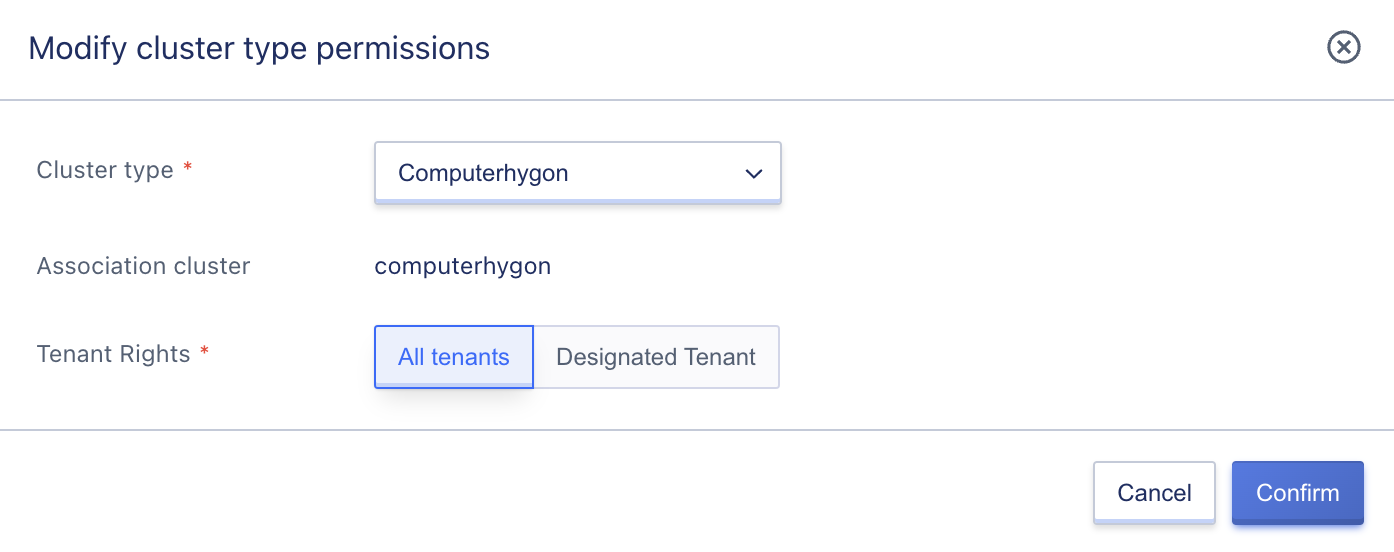
The default permission is “All Tenants,” which means all platform tenants can deploy virtual resources to all clusters by default. When the administrator sets tenant permissions for a cluster to “Specified Tenants,” only the specified tenants can view and deploy virtual resources to the cluster.
4.1.4 CPU Oversubscription
Oversubscription refers to allocating the same type of resources in excess of standard physical resource allocation to different application loads (virtual machines) during the same time period for sharing purposes. The CPU oversubscription can be calculated by dividing the total number of virtual CPUs of all running virtual machines on a single physical server by the total number of physical CPU cores on that server. The result is generally expressed as n:1. Platform administrators can adjust the CPU oversubscription ratio at the computing cluster level to fully utilize cluster resources. Please adjust the CPU oversubscription ratio while considering the actual CPU usage of the platform and do not oversubscribe excessively, as it may affect system performance. The adjustment of CPU oversubscription takes some time to take effect, and the number of cores available for allocation through oversubscription is based on the oversubscription result. The expected data provided is for reference only. 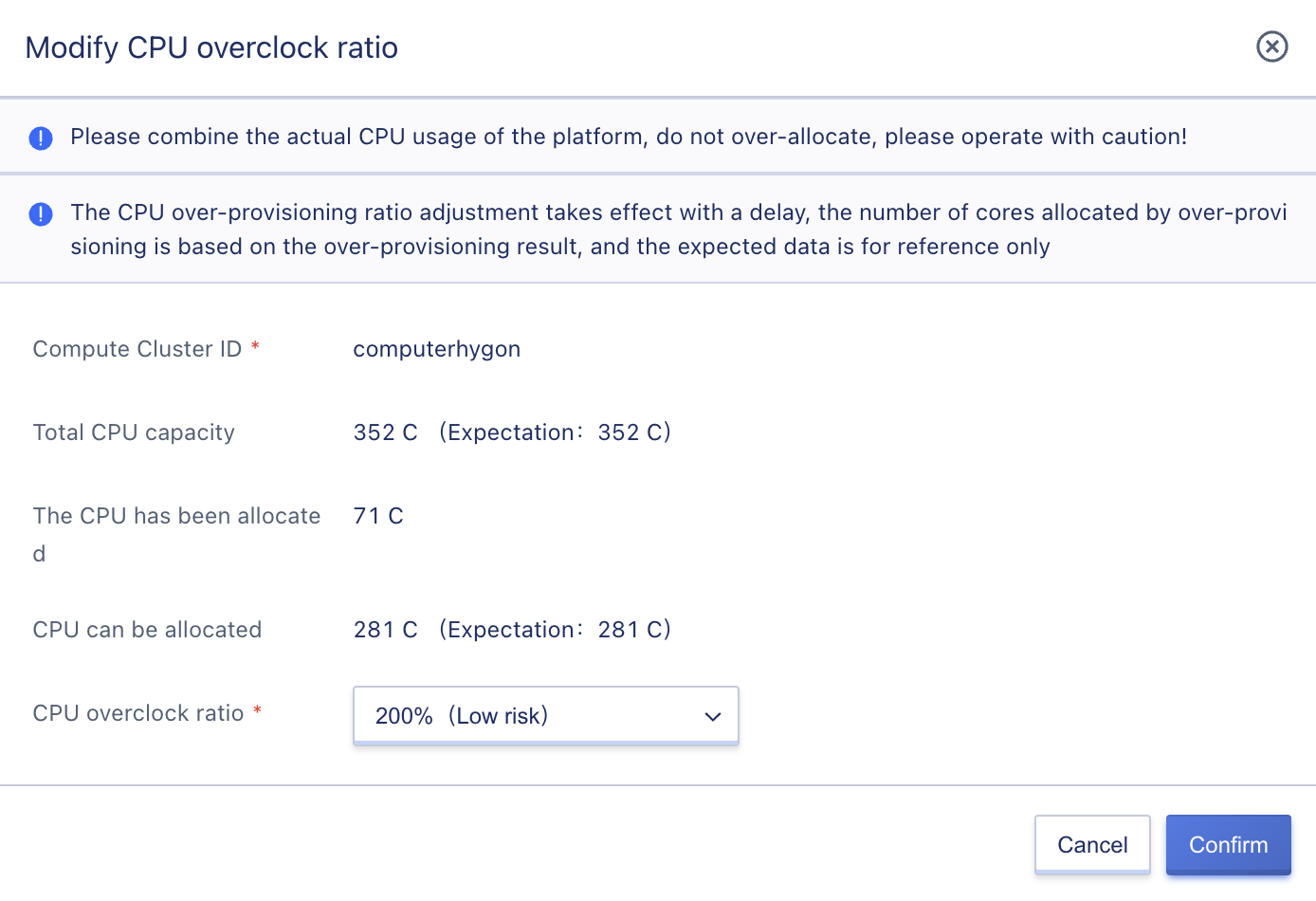
4.1.5 Compute Instance Management
Compute instance management refers to the platform administrator’s management of all compute instances within a computing cluster, including virtual machine instances deployed by platform tenants in the cluster and compute instances of PaaS products such as load balancers, NAT gateways, and VPN gateways. The platform provides lifecycle management of compute instances, including viewing compute instances, live migration, and offline migration. Administrators can use compute instances to understand the specific situation of cluster resources.
4.1.5.1 Viewing Compute Instances
Administrators can enter the details page through the “Computing Cluster” list and switch to the “Compute Instance” tab to view and manage the compute instance list and related information under the computing cluster, including the compute instance name, instance ID, resource ID, tenant, private IP, host IP, image ID, GPU, CPU, memory, state, creation time, and update time, as shown below:
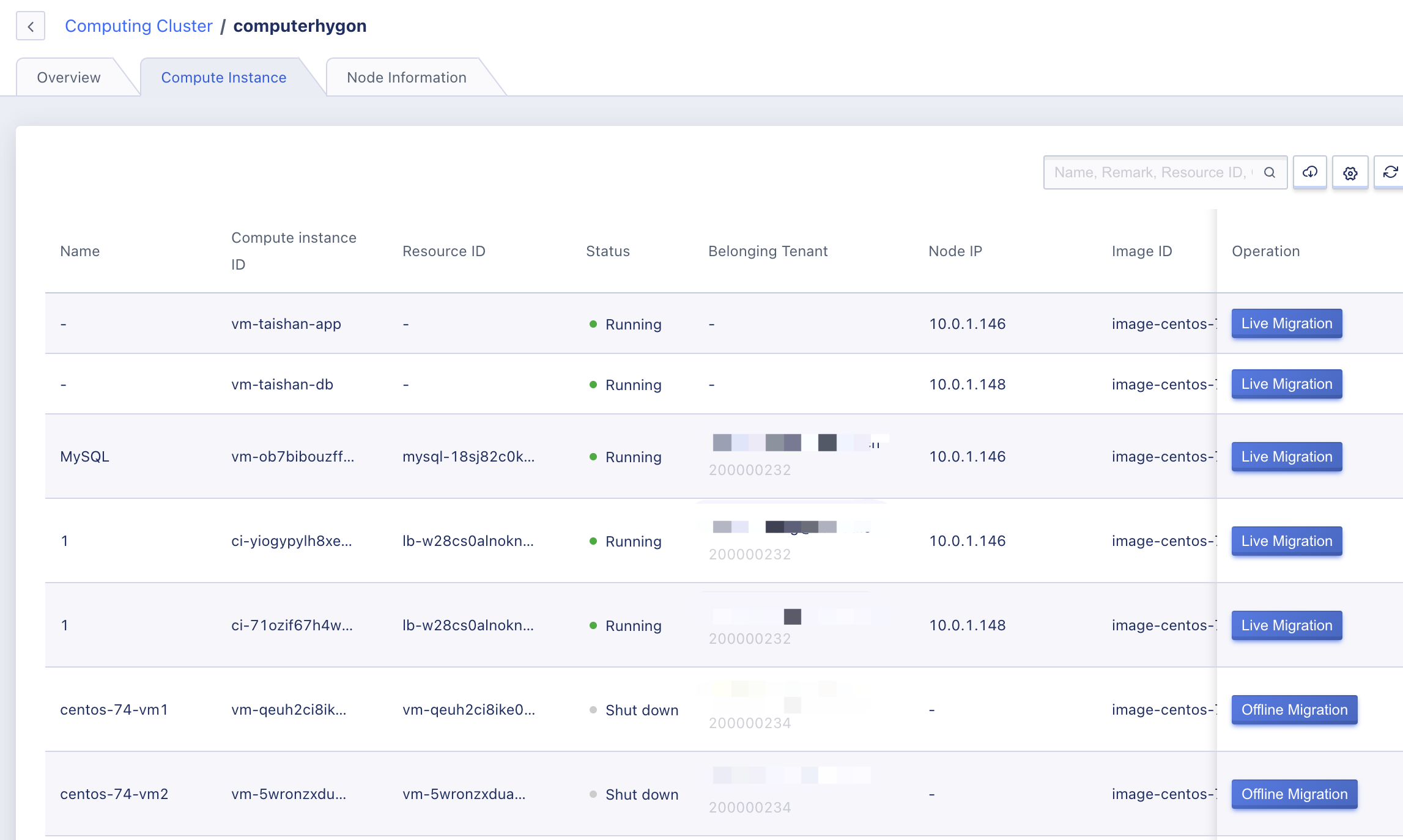
- Name: the name of the corresponding resource of the compute instance. When the compute instance is a virtual machine, the virtual machine name is displayed. When the compute instance is an instance of a PaaS product, the name of the PaaS product resource is displayed, such as lb001.
- Compute Instance ID: the identifier of the compute instance in the corresponding underlying computing instance.
- Resource ID: the identifier of the compute instance in the platform.
- Tenant: the email address of the tenant that owns the compute instance.
- Host IP: the IP address of the host where the compute instance is deployed. Since the compute instance does not occupy CPU and memory resources when it is shut down, the physical machine IP is empty when the compute instance is shut down.
- Private IP: the private IP address of the compute instance.
- Image ID: the ID of the operating system image used by the compute instance.
- GPU: the number of GPUs of the compute instance.
- CPU: the number of vCPUs of the compute instance.
- Memory: the memory capacity of the compute instance.
- State: the state of the compute instance, including creating, booting, running, shutdown, poweroff, reinstalling, deleting, and migrating. The migration status includes live migration and offline migration.
- Creation Time: the creation time of the compute instance.
- Update Time: the update time of the compute instance.
4.1.5.2 Live Migration
Live migration is a planned migration operation that allows virtual machines to be migrated between different physical machines online without downtime. Live migration can balance the load of computing nodes, migrate virtual machines that communicate with each other to a single computing node, and distribute multiple virtual machines to different computing nodes for various scenarios, improving the availability and reliability of the platform and services.
During live migration, a virtual machine process with the same configuration as the target host will first be registered on the destination host, and then the memory data of the compute instance will be synchronized, and finally the business will be quickly switched to the target instance. The entire migration switch process is very short and almost does not affect or interrupt the business running in the instance, which is suitable for cloud platform resource dynamic adjustment, host maintenance shutdown, and optimization of server energy consumption, etc., further enhancing the reliability of the cloud platform.
The live migration of compute instances supports two modes: random assignment and specified physical node, to adapt to different migration tasks:
- Random assignment: the platform randomly assigns a physical machine as the target node for the migration of the compute instance based on the load situation of computing nodes in the cluster.
- Specified physical node: the migration has a specific target node. The platform designates the specified node as the target node for the migration of the compute instance.
Administrators can choose the appropriate migration mode based on specific needs, and the default mode is random assignment. If there is a clear target node for migration, such as the current physical machine where the virtual machine is located has a high load, it can be migrated to a known physical machine with a lower load, and the specified physical node migration mode can be selected, and the target node can be selected according to the host IP; if there is no clear target node, the random assignment migration mode can be selected, and the system will automatically select a suitable physical node. The prerequisites for live migration are as follows:
- The compute instance is in normal running state.
- The cluster where the instance is located has sufficient resources to meet migration requirements.
- The compute instance does not mount GPU devices, that is, it does not support migration of GPU virtual machines.
- The business deployed by the virtual machine does not have frequent read and write operations, otherwise the migration process may be slow or unable to complete.
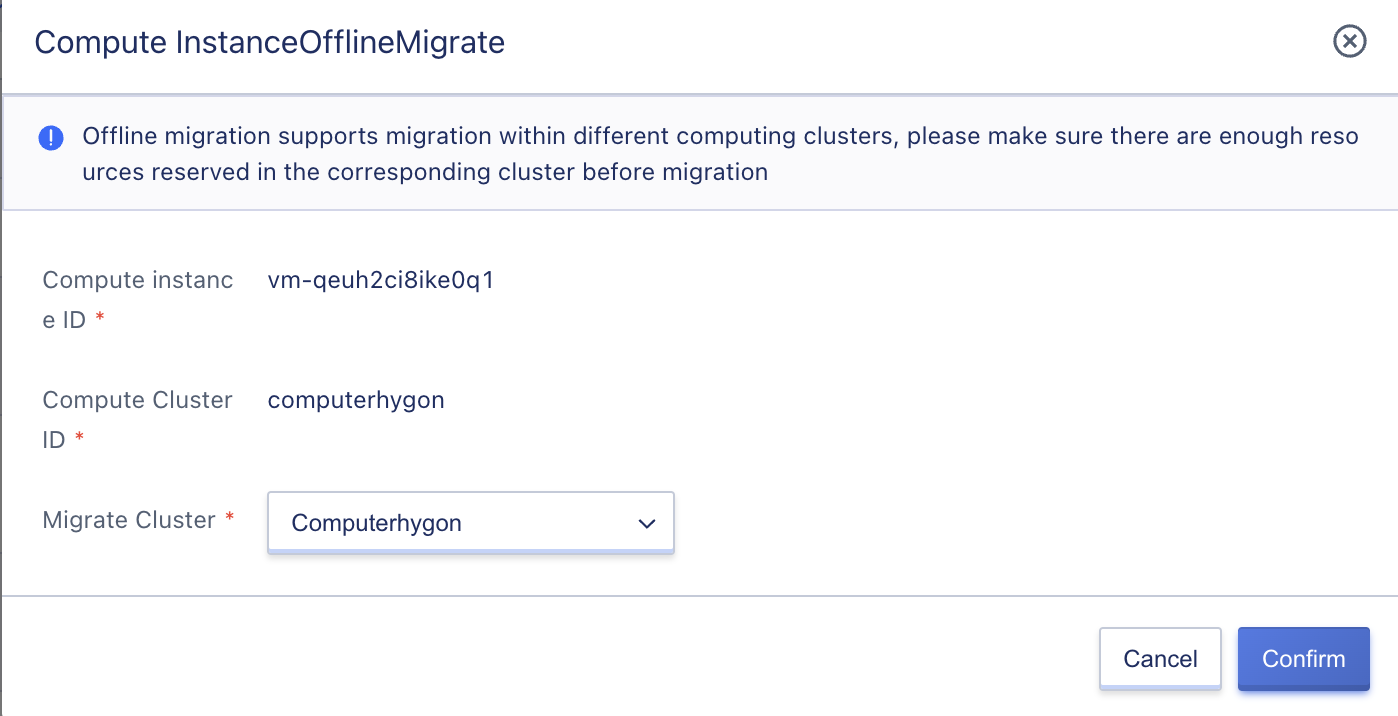
Administrators can perform online migration operations by selecting the “Migration” option in the “Compute Instance” list of operations, specifying the migration mode and target node to migrate the instance, as shown in the following figure:
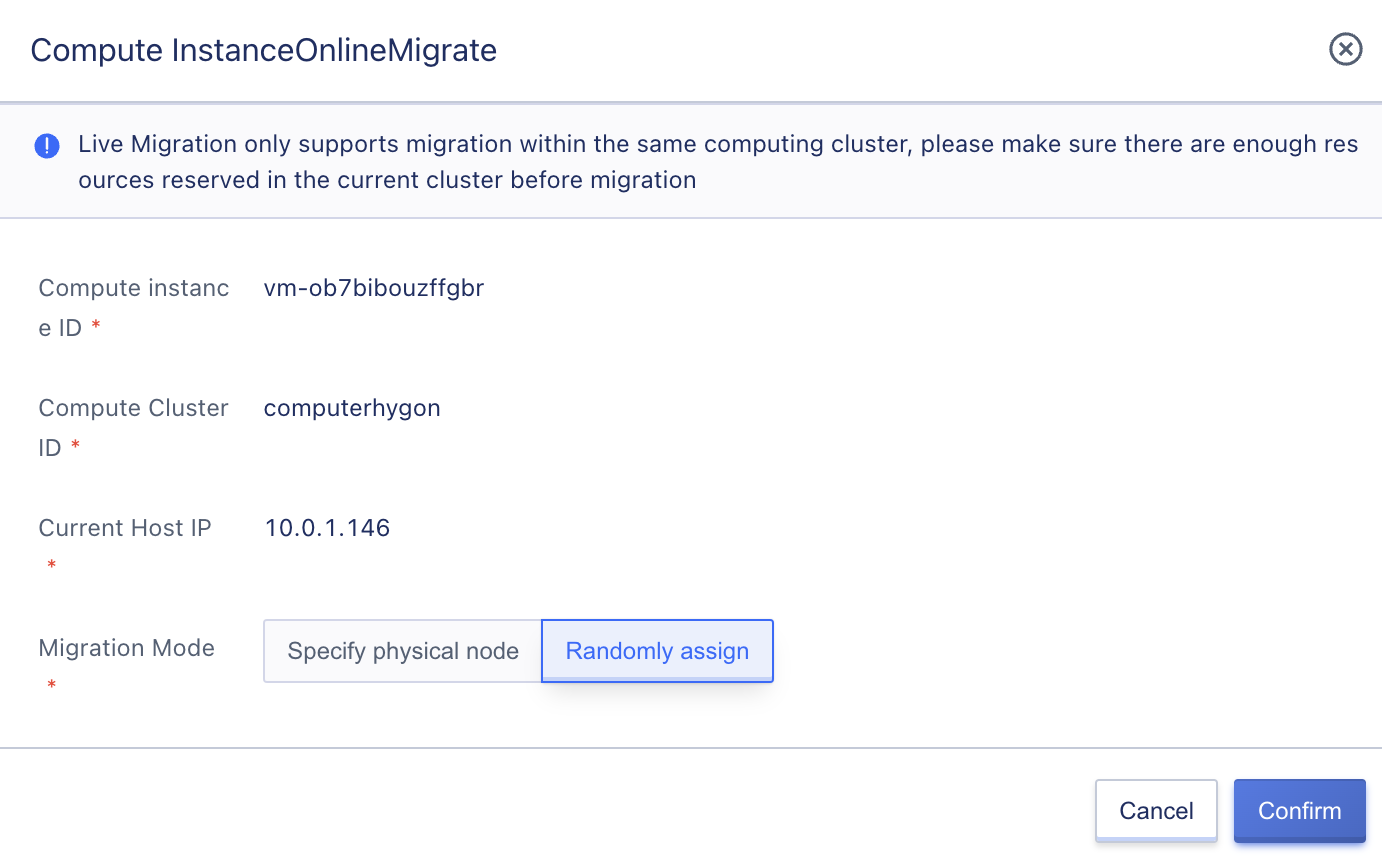
Online migration only supports migrating within the same compute cluster. The instance’s state changes to “migrating” during the migration process and switches to the “running” state after successful migration. During online migration, the full and incremental memory data of the source instance are migrated, and the migration process is completed after the memory data synchronization is iterated repeatedly.
4.1.5.3 Offline Migration
Offline Migration:Offline migration refers to pausing the virtual machine before migration. If shared storage is used, only the system status is copied to the destination cluster, and the virtual machine status is rebuilt on the destination cluster for execution. If local storage is used, the virtual machine image and status need to be copied to the destination cluster. This migration method requires explicitly stopping the virtual machine’s operation, resulting in a clearly defined period of service unavailability from the user’s perspective. This migration method is simple and easy to implement and is suitable for scenarios where service availability requirements are not strict.
Offline migration supports migration between different compute clusters. Please ensure that sufficient resources are reserved in the corresponding cluster before migration. Offline migration is not supported between different cluster architectures.
4.1.5.4 Crash migration
Crash migration, also known as offline migration or virtual machine high availability, refers to the platform’s underlying host failing due to an exception or malfunction, causing the virtual resources it carries to be quickly migrated to a healthy and normally loaded host to maintain business availability as much as possible.
The overall crash migration does not involve storage and data migration. A new compute instance can quickly run on a new host, with an average migration time of about 90 seconds, which may affect or interrupt the business running in the virtual machine. The crash migration is an automatic trigger behavior of the platform’s intelligent scheduling system, and the entire process does not require manual intervention. Administrators can view the crash migration process through the state of the compute instance list. During the crash migration process, the instance state is “migrating”, and after the compute instance successfully starts up on a healthy node and runs normally, its state changes to “running”.
The platform provides compute instance crash migration based on the cluster, which refers to redeploying the compute instance to a healthy and normally loaded host node in the cluster when the host where the compute instance belongs fails. Typically, it is recommended to plan host nodes with the same CPU and memory configurations as a compute cluster to avoid virtual machine anomalies or failures to start due to inconsistent CPU architecture or configuration after migration.
4.1.6 Cluster Host Management
Cluster host management refers to the management of all computing nodes in the cluster by administrators, such as locking hosts, entering maintenance mode, etc. Cluster host management operations are consistent with host management in resource management, except that cluster host management manages computing nodes within this cluster, while host management in resource management manages all computing nodes in the region. See the “Host Management” section in Resource Management for specific management operations.
4.2 Storage Cluster
The storage cluster platform provides a default distributed storage cluster, which typically consists of a group of identically configured storage nodes (hosts) for deployment and hosting of distributed storage resources. Multiple types of storage clusters can be deployed in a data center, such as SSD clusters, SATA clusters, capacity-based clusters, performance-based clusters, etc. Different clusters can provide different types of cloud disk sources, such as an SSD storage cluster that can provide tenants with SSD-type cloud disks.
The platform provides basic storage resources through a distributed storage cluster architecture and supports online horizontal scaling. It integrates intelligent storage clusters, multi-copy mechanisms, data rebalancing, fault data reconstruction, data cleaning, automatic thin provisioning, and snapshot technologies to provide high-performance, high-reliability, high-scalability, easy management, and data security guarantees for virtualized storage, comprehensively improving the service quality of storage virtualization and cloud platforms.
The default distributed storage cluster supports a 3-copy strategy, where data is written to the primary replica first when writing data, and the primary replica is responsible for synchronizing the data to other replicas, with each copy stored on different disks across servers and cabinets to ensure data security from multiple dimensions. When there is no network interruption or disk failure in the storage server nodes in the storage cluster, the replica data always remains at 3 copies, without distinguishing between primary and backup replicas. When the number of abnormal replicas is less than 3 due to storage node failures, the storage system will automatically reconstruct the data replicas to ensure that the data replicas are permanently maintained at three, providing data security for virtualized storage.
The platform allows administrators to manage storage clusters, including viewing storage clusters, modifying the name and permissions of the cluster type, etc., which can be managed through the storage cluster page in the management console.
4.2.1 View Storage Cluster
Different types of storage clusters can be deployed in different regions, such as SSD, SATA, SAS, etc., and the cluster name is usually set according to the storage medium or storage usage. Administrators can also modify the cluster names based on deployment environment information. The platform storage cluster management console can be accessed through “Cluster Management” -> “Storage Clusters” in the navigation bar, or by managing specific region storage clusters through “Regions Details” -> “Storage Clusters”.
Administrators can view a list of all storage clusters and their information in a specific region through the storage cluster console, including cluster ID, cluster type, cluster type name, cluster architecture, storage usage, and update time, as shown in the figure below:
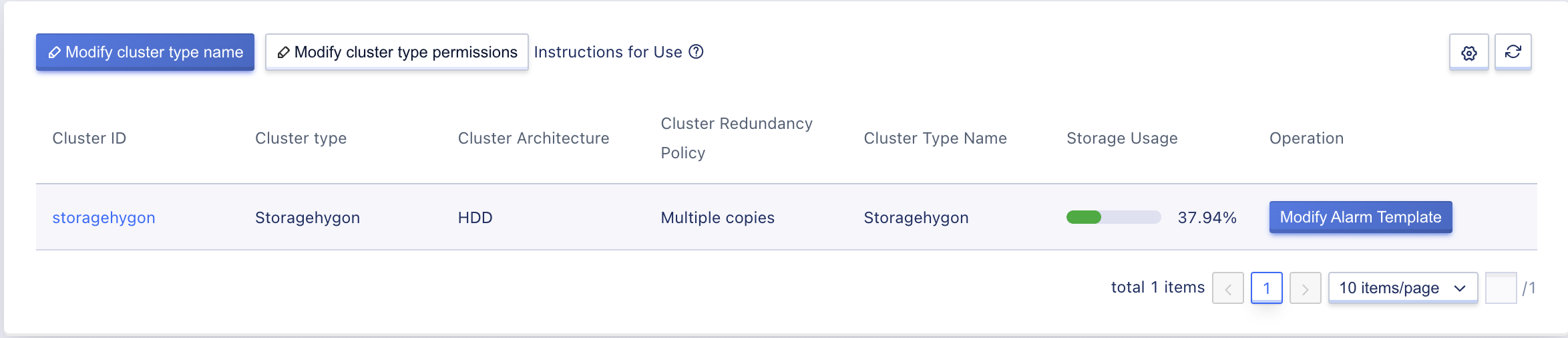
- Cluster ID: The globally unique identifier for the storage cluster platform, such as storage-set-01.
- Cluster type: the type of storage cluster.
- Cluster type name: the name that represents the storage cluster type, which is the disk type in the tenant client. Tenants can choose different storage types to create cloud disks when creating virtual machines. A storage cluster type may contain multiple storage clusters.
- Cluster architecture: the architecture of the storage cluster, such as SSD.
- Storage usage: represents the total capacity of the storage cluster, in GB.
- Update time: the update time of the storage cluster.
4.2.2 Modify Cluster Type Name
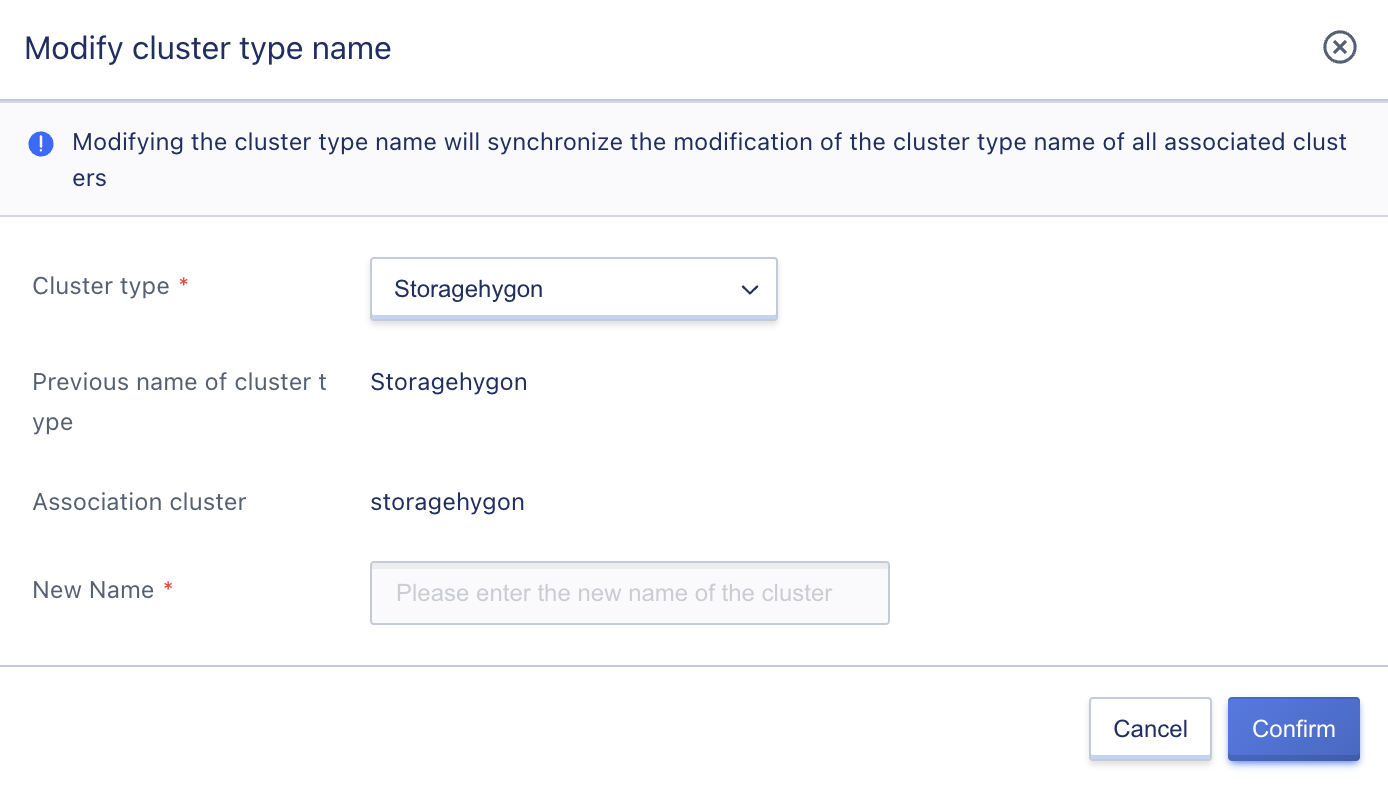
By default, the platform sets the cluster name based on the storage medium or storage usage. Platform administrators can name storage clusters with more distinctive names according to their platform usage requirements.
After modifying the cluster type name, the disk type selected by users when creating a cloud disk will be synchronized with the cluster type name. Changing the name does not affect the normal operation of the cluster and resources, and can be modified under any circumstances. Administrators can click “Modify Cluster Type Name” in the storage cluster list and enter the new name to change the cluster type name, as shown below:
4.2.3 Modify Cluster Permissions
The platform’s storage clusters are open to all tenants by default. The platform supports permission control for storage clusters, which is used to allocate some physical storage resources exclusively to one or some tenants for use, suitable for exclusive private cloud scenarios. After modifying the cluster permissions, the cluster can only be opened and used by specified tenants. Tenants without permission cannot view and use restricted clusters to create cloud disk resources.
To enable tenants to exclusively use some hosts, when planning physical resources on the deployment platform, it is necessary to divide the exclusive hosts into an independent computing cluster, and also divide the storage resources on the exclusive hosts into an independent storage cluster, and assign the divided computing and storage clusters to the exclusive tenant to ensure that the computing and storage resources assigned to the tenant are from the same exclusive host.
Platform administrators can click “Modify Cluster Type Permissions” in the storage cluster list to specify tenant permissions as “All Tenants” or “Specified Tenants” to allocate the cluster to the specified tenants, as shown below:
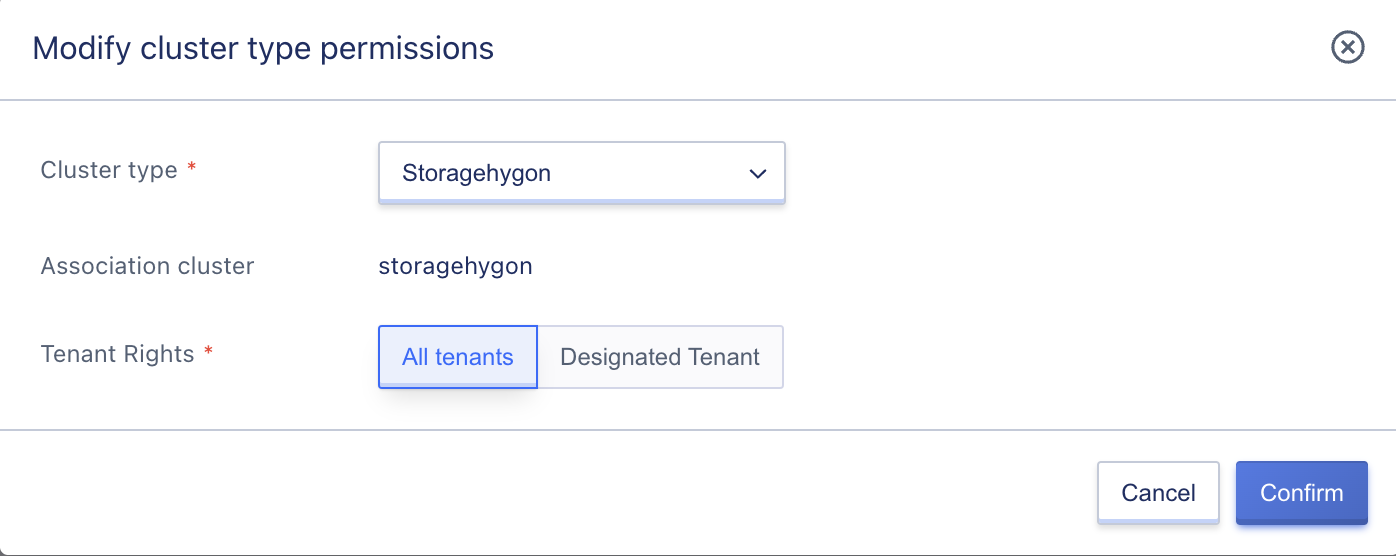
The default permission is “All Tenants,” which means that all tenants on the platform can create and use cloud disk resources on all storage clusters by default. When a user sets tenant permissions for a cluster to specified tenants, only the specified tenants can view and use the storage resources of the cluster.
4.3 External Storage
4.3.1 Product Introduction
The cloud platform provides distributed storage as the backend storage for virtualization by default, providing high availability, high performance, high reliability, and high security storage services for cloud platform users. At the same time, the cloud platform virtualization supports commercial storage devices such as IPSAN and other storage arrays, providing high-performance block storage services for virtual machines in the cluster, while also enabling enterprise users to utilize centralized storage devices, saving the overall cost of information technology transformation.
External storage services are commercial storage services provided by the cloud platform for enterprise users. Through ISCSI protocol and FC protocol, commercial storage is connected as a backend storage pool for virtualization, providing storage pool management and logical volume allocation. It can be used directly as a system disk and data disk for virtual machines. Any storage device that supports ISCSI protocol and FC protocol can be used as the backend storage for the platform virtualization, adapting to multiple application scenarios.
The platform supports the connection and management of storage devices, and supports the allocation of LUNs in storage devices to tenants. Tenants can assign or mount LUNs to the system disks or data disks of virtual machines for data read and write. The specific functional features are as follows:
- Support the entry and management of storage device resource pools, and support one-click scanning of LUN storage volume information created in ISCSI devices.
- Support scanning of LUN storage volume information already created in FC-SAN devices connected to the cloud platform.
- Support assigning scanned LUN storage volumes to platform tenants, giving them permission to use the disk as virtual machine system disk or data disk.
- Support tenants using authorized LUN storage volume information as virtual machine system disks so that virtual machines can run directly on commercial storage, improving performance.
- Support tenants using authorized LUN storage volume information as virtual machine data disks.
- Support reallocating storage volumes to other platform tenants.
Based on the above functional features, the platform can directly use commercial storage devices as backend storage for virtualization, providing virtual machines with storage space of traditional commercial storage devices, while not affecting other LUNs in commercial storage that provide storage services for other businesses.
The platform connects commercial storage through ISCSI protocol and FC protocol, and needs to map the LUN of the storage device to the platform computing node during connection, so that the virtual machine running on the platform computing node can directly use the mapped LUN. At the same time, to ensure high availability of virtual machines, LUNs need to be mapped to all computing nodes in a cluster, so that all computing nodes can mount and use the mapped storage volume to ensure that the storage volume information can be mounted on each computing node when there is a failure migration.
- When the computing node on which the virtual machine resides fails, the platform will automatically trigger a virtual machine crash migration, that is, migrate the virtual machine to a normal computing node in the computing cluster so that the virtual machine can provide services normally.
- The LUN storage volume used by the virtual machine has been mapped to all computing nodes in the cluster. After the virtual machine is migrated to a new node within the cluster, it can directly use the mapped LUN storage to start the system disk or data disk of the virtual machine, and mount it normally to the virtual machine to ensure that the business is normal after the virtual machine is migrated.
The platform only uses commercial storage LUNs as storage volumes, and does not manage the storage volumes themselves, such as creating, mapping, expanding, snapshotting, backing up, rolling back, cloning, etc.
4.3.2 Usage Process
Before using external storage, the platform administrator or storage device administrator needs to connect the external storage to the computing node network of the platform, so that the computing nodes can directly communicate with the storage devices on the internal network.
After the physical storage device and network are ready, you can dock with the platform and use the external storage services provided by the platform. The entire docking process requires three roles: storage device administrator, platform administrator, and platform tenant. Among them, the operations related to the platform are the operations of the platform administrator and the platform tenant. Taking ISCSI protocol as an example, the process is as follows:
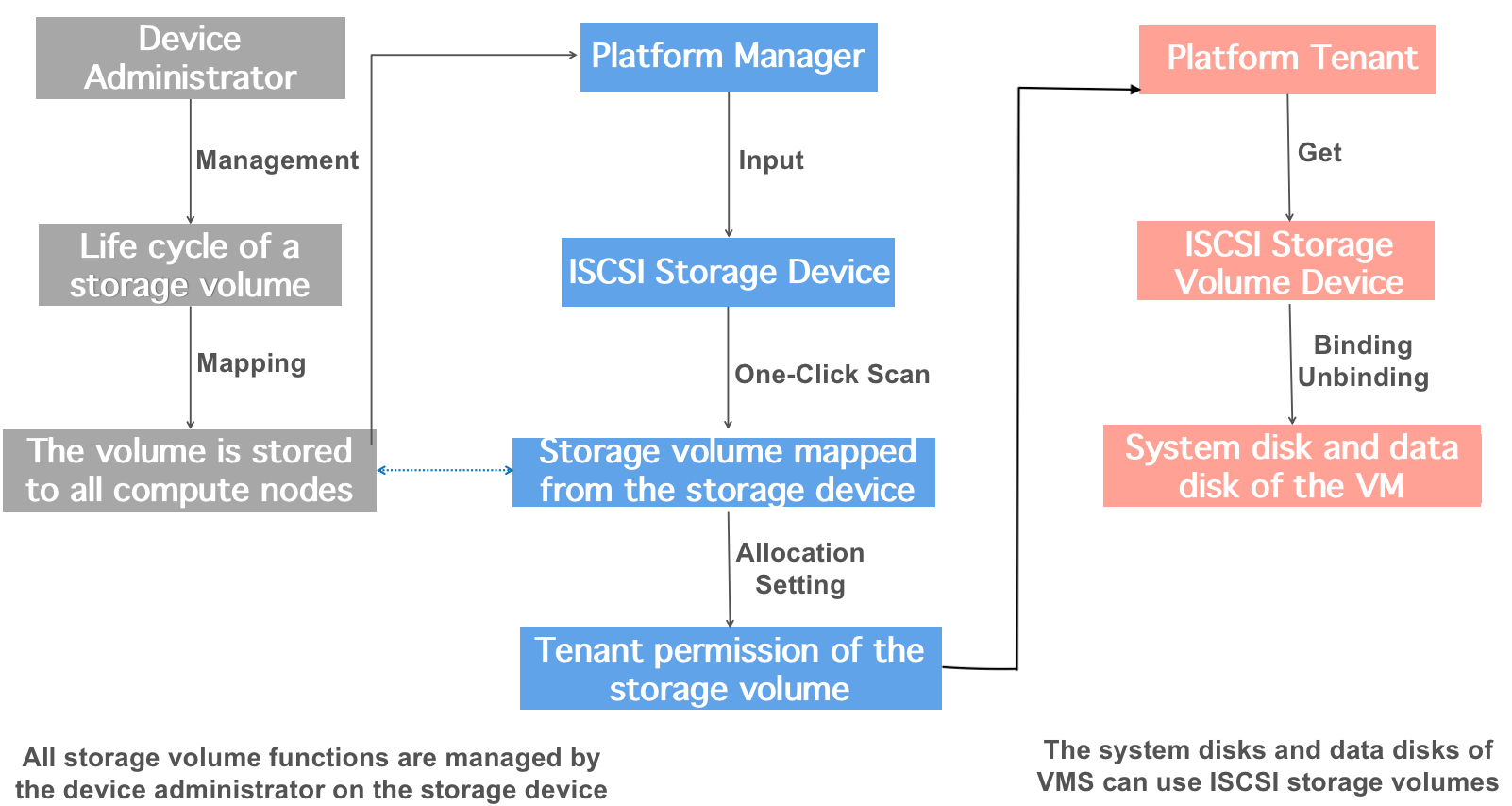
-
Storage device administrator manages storage volumes
All storage volume management is operated by the storage device administrator on the commercial storage management system, including creating and mapping storage volumes (Lun), as well as related lifecycle management such as expansion, snapshotting, backup, and deletion of storage volumes.
-
Storage device administrator maps storage volumes to cluster computing nodes
The created Lun is mapped by the storage device administrator to all computing nodes on the storage device (if a new computing node is added, mapping needs to be performed again), and multiple path mappings can also be performed.
-
Platform administrator enters and manages storage devices
After the storage volume LUN is successfully mapped, the [platform administrator] enters the ISCSI storage pool or storage device in the “External Storage Cluster” of the management console, and specifies the ISCSI address of the storage device when entering, such as 172.18.12.8:8080.
-
Platform administrator scans already mapped LUN information
录After the storage device is entered, the [platform administrator] performs a one-click scan of the storage volume devices and information that have been mapped to the cluster nodes in the ISCSI storage device.
-
Platform administrator assigns LUN devices to tenants
The [platform administrator] designates the successfully scanned LUN storage volume device to the tenant, and one storage volume can only be assigned to one tenant at a time. After the assignment, the tenant can query the allocated storage volume device in the external storage device and create or mount a virtual machine.
-
Platform tenant uses LUN storage volume device
Platform tenants can directly query the allocated storage volumes through the external storage console, and specify the system disk type as external storage when creating a virtual machine, or directly mount the LUN storage volume device to an existing virtual machine as a data disk.
The premise of platform tenants using external storage services is that the storage volume has been mapped and assigned to the tenant, and the tenant only needs to bind it simply to use the external storage device provided by the platform conveniently, and can perform flexible binding and unbinding.
4.3.3 Adding External Storage
Before using external storage, the platform user needs the administrator to add the external storage to the cloud platform on the control panel. When adding, you need to specify the ISCSI address of the commercial storage, which is the ISCSI entry point for the platform to connect to the commercial storage, usually composed of IP and port. When adding external storage, multiple ISCSI addresses can be added to one commercial storage for multi-path access to ensure the availability of LUN storage access.
Administrators can enter the external storage console through the navigation bar to enter the cluster management and switch to the external storage console. Through the [New] operation, they can enter the Add External Storage Wizard page, as shown below:
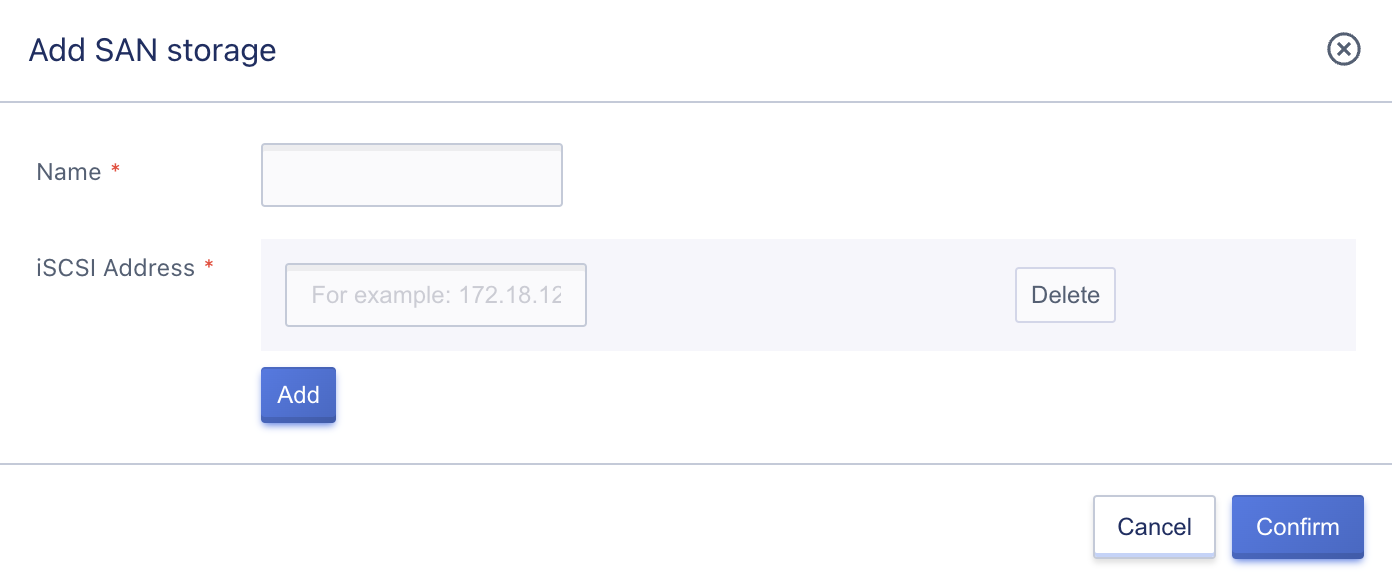
- Name: The name of the external storage, which must be specified when adding.
- ISCSI Address: The ISCSI connection address of the external storage, in the format of IP:Port, supports adding multiple ISCSI addresses, such as 172.16.13.201:3260 and 172.16.13.202:3260.
After adding, a piece of external storage information will be generated in the external storage list, and you can view the information of the external storage and the mapped LUN storage volume information on the platform.
4.3.4 Viewing External Storage
Administrators can view the list information of external storage, including name, resource ID, status, ISCSI address, LUN quantity, and operation items, as shown below:
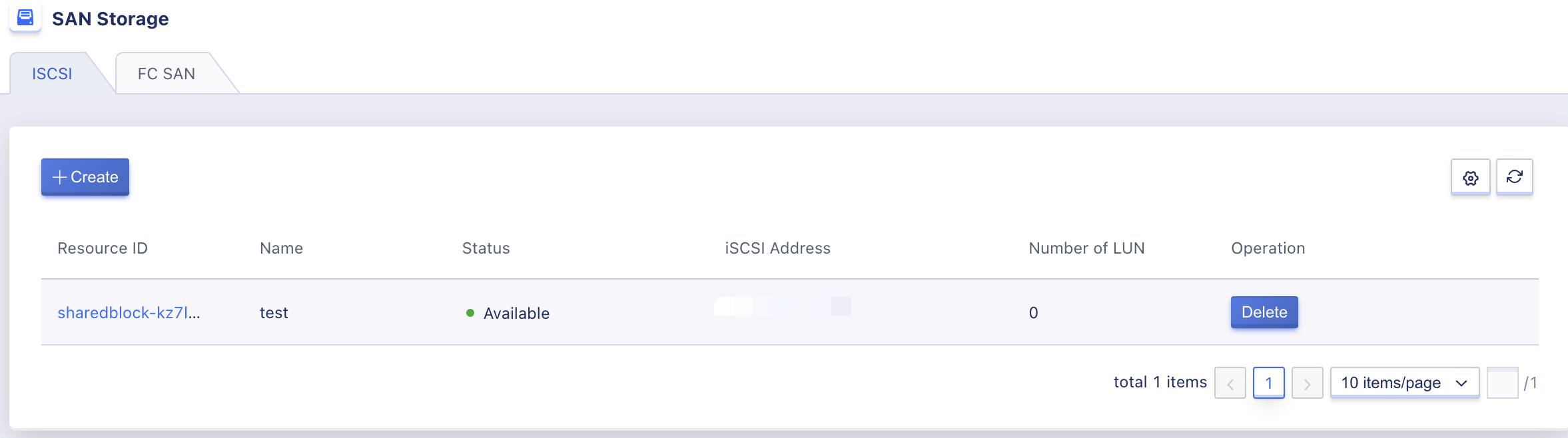
- Name: The name and identification of the external storage, displayed as the name of the system disk type when creating a virtual machine on the tenant side.
- Resource ID: The global unique identifier of the external storage on the platform.
- ISCSI Address: The ISCSI connection address of the external storage, which can be multiple.
- LUN Quantity: The number of LUN storage volumes that have been mapped to the platform on the external storage.
- Status: The status of the external storage.
Each external storage in the list can be deleted, and by clicking on the details, you can enter and manage the LUN storage volume of the commercial storage.
4.3.5 Scanning LUN Storage Volumes
After adding external storage to the cloud platform, the platform administrator needs to perform a one-click scan of the LUN storage volumes that have been mapped to the platform from the storage device so that the platform can obtain the available LUN device information.
The platform administrator can click the “Scan” button in the “LUN Storage Volume” list of the external storage details to scan the LUN storage volumes. After triggering the scan, the LUN storage volumes mapped by the commercial storage device administrator to the platform computing node will be displayed in the LUN storage volume list. You can view the information of the LUN storage volume through the list and assign it to the designated tenant for creating a virtual machine or mounting as a data disk to a virtual machine.
When the storage device administrator adds a new LUN on the storage device and maps it to the platform, they can rediscover the newly mapped storage volume through scanning and allocate the new storage volume to the tenant for creating virtual machines and mounting data disks.
4.3.6 Viewing Storage Volume Information
The administrator can view the scanned storage volume information through the “LUN Storage Volume” list in the external storage details, including name, LUNID, resource ID, capacity, status, mounted resources, belonging tenant, and operation items, as shown below:
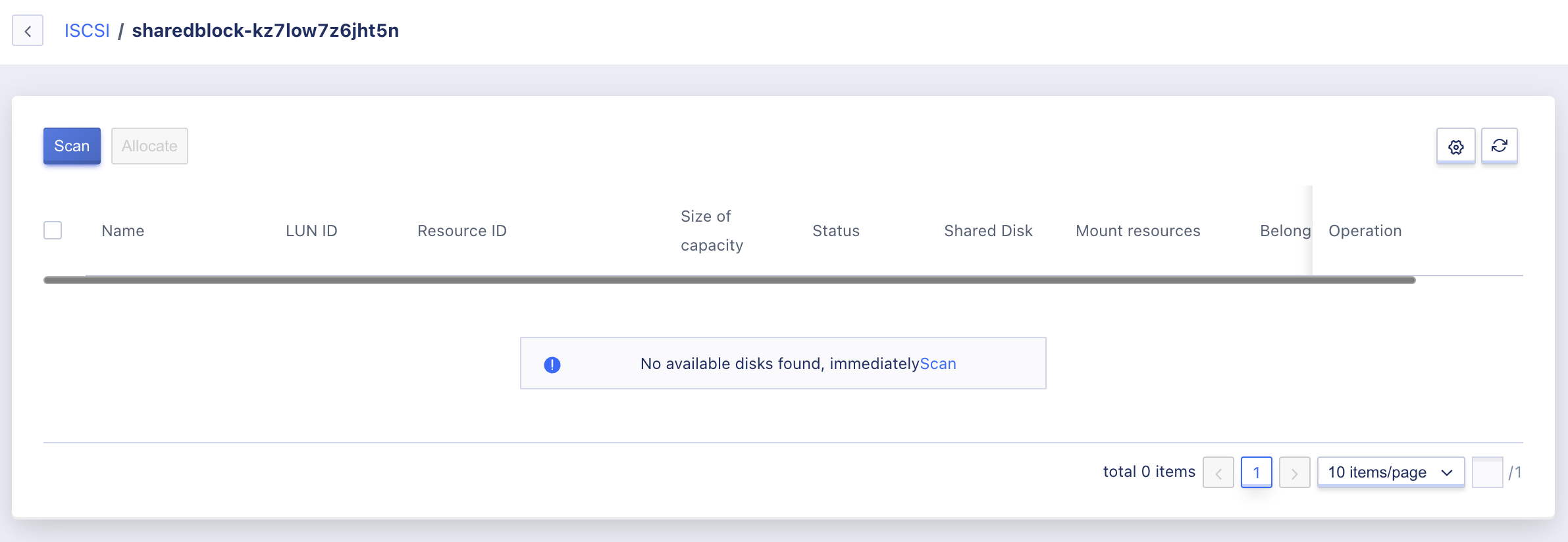
- Name: The name of the LUN storage volume.
- LUNID: The unique identifier of the LUN storage volume in the commercial storage.
- source ID: The unique identifier of the storage volume on the platform.
- Capacity: The current capacity of the LUN storage volume.
- Status: The current status of the LUN storage volume, including unbound, binding, bound, unbinding.
- Mounted Resources: The ID of the virtual machine that the LUN storage volume has been mounted to. It is empty when unbound.
- Belonging Tenant: The email address of the tenant to which the LUN storage volume has been assigned.
Through the operation item on the list, you can assign each LUN storage volume information to a tenant, which means assigning the storage volume to a tenant.
4.3.7 Assigning storage volumes to tenants
The platform supports platform administrators to assign LUN storage volume information that has already been scanned in commercial storage to a tenant, giving the tenant permission to use the LUN as a system disk or data disk for virtual machines. It also supports modifying the ownership of storage volumes, i.e., reassigning a storage volume from one tenant to another. A storage volume can only be assigned to one tenant at a time and can only be mounted to one virtual machine at a time.
Administrators can assign a LUN storage device to a tenant through the “Assign” operation on the LUN storage volume list, as shown below:
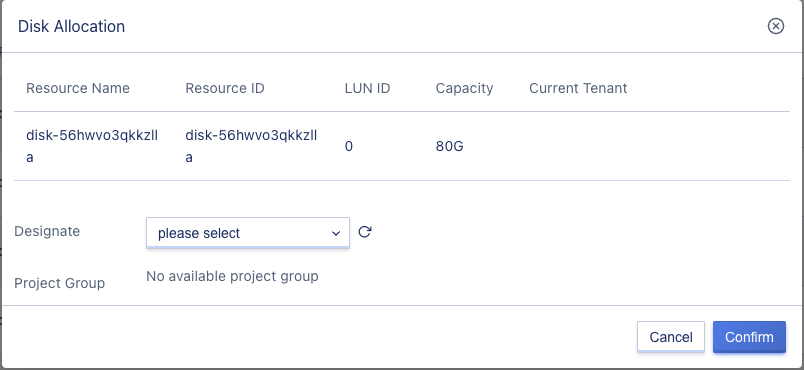
Administrators can also reassign a storage volume to another tenant using the assignment operation, but only LUN devices in an unbound state can be reassigned.
4.3.8 Deleting External Storage
The platform supports administrators to delete external storage, and all the LUN devices scanned before deletion must be in an unbound state. The external storage can be deleted through the “Delete” option in the external storage resource list operation, as shown below:
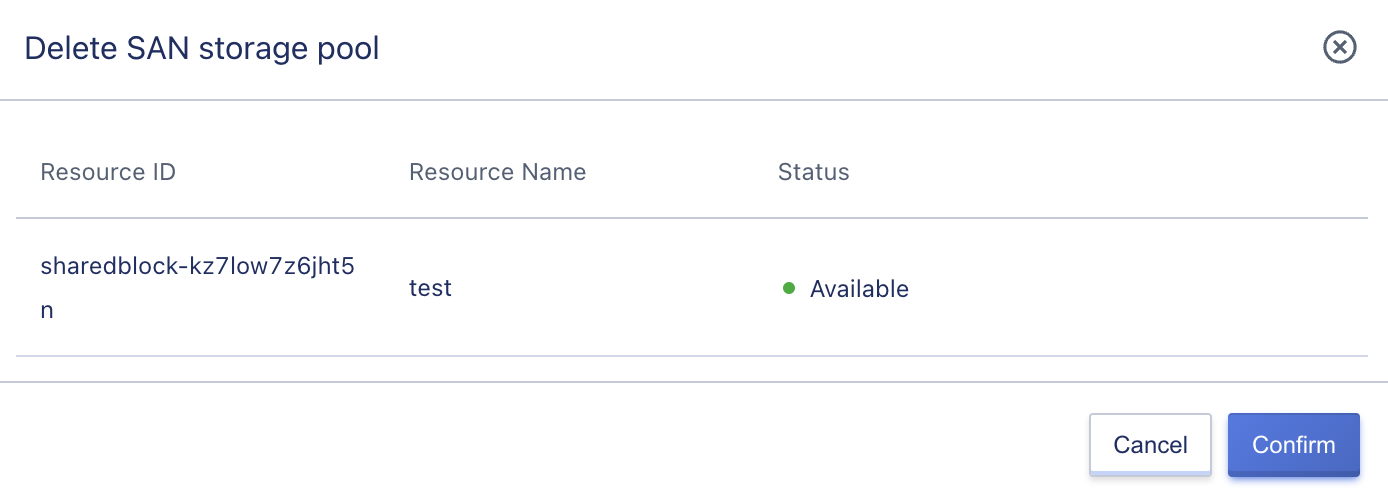
Deleting external storage only means releasing the device from the platform, and it can be added back to the cloud platform by entering the ISCSI address.